 DATA PORTFOLIO
DATA PORTFOLIO
Welcome to my data portfolio! Here you can find a selection of my projects and skills in data science and analytics.
Table of Contents
Achievements
- Recipient of Graduate Merit Scholarship Package at the American University, Washington D.C (2024-)
- BSc in Economics Graduate from the London School of Economics (LSE), United Kingdom (2021-2024)
I have a website on which you can see some of projects and blogs as a MS Data Science student.
Projects
Projects I have worked on:
 AI Discourse at Scale: Topic, Sentiment, and Community Dynamics Across Reddit
AI Discourse at Scale: Topic, Sentiment, and Community Dynamics Across Reddit
This project analyzed 4.2 billion Reddit comments and submissions from June 2023 to July 2024 using Apache Spark. It built a scalable ETL pipeline that filtered 445 GB of parquet archives into AI-focused subreddit clusters. Spark NLP performed sentiment analysis, topic modeling, and temporal aggregation over 14 months. Processing by subreddit and month generated summaries of comment volume, unique users, and activity spikes, revealing discourse drivers. The project provides a reproducible snapshot of digital conversations during a tech inflection point, showcasing scalable distributed data engineering for behavioral analytics with an efficient pipeline for billion-row datasets, supporting real-time community insights with PySpark, Spark NLP, parquet I/O, distributed aggregations, and an interactive website.
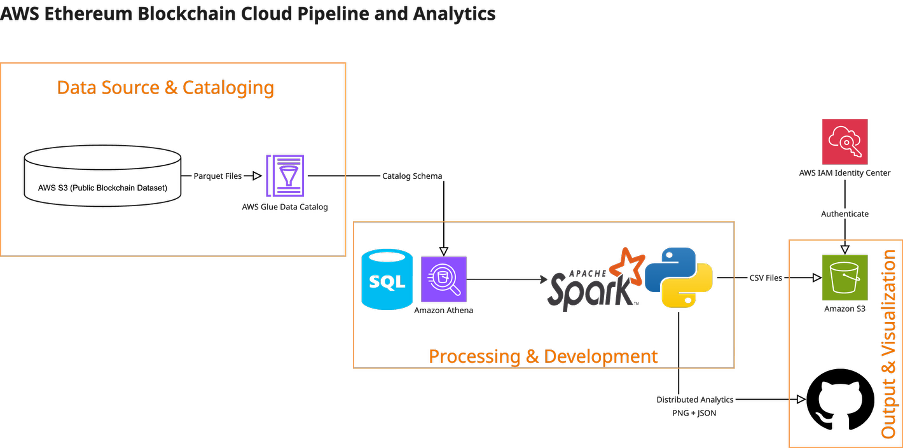 AWS Public Blockchain Analysis with Athena & PySpark
AWS Public Blockchain Analysis with Athena & PySpark
This project explores Ethereum’s on-chain activity using AWS Athena, S3, and PySpark for large-scale SQL querying, data transformation, and visualization. Transaction-level data from the public blockchain lake was queried via boto3, processed in distributed Spark DataFrames, and visualized in Python. Final analysis quantifies consistent daily throughput (~1.6 M tx/day) and how gas markets, congestion, and wallet networks interact—demonstrating the power of cloud-based analytics pipelines for real-time blockchain intelligence.
 Scrollytelling with Quarto: Close Read Prize Contest
Scrollytelling with Quarto: Close Read Prize Contest
This project analyzes the financial risk of semiconductor stocks using O-GARCH and Value-at-Risk (VaR) models in R to assess stock volatility and investment risks. The findings are presented on a personal website built with the R library ‘qmd-lab/closeread’, HTML and CSS. Examining stock volatility and investment risks highlights key factors influencing market fluctuations and helps investors make informed decisions.
 Assessing Bias in Mortgage Lending Using Supervised Machine Learning Methods
Assessing Bias in Mortgage Lending Using Supervised Machine Learning Methods
I applied Python-supervised machine learning algorithms to assess bias in mortgage lending decisions. The project predicts loan approval outcomes based on applicant data, mitigating bias and improving decision-making processes in mortgage lending through data-driven insights.
 SmartRetail: Customer Segmentation for Micro-Targeting
SmartRetail: Customer Segmentation for Micro-Targeting
I implemented customer segmentation techniques to enhance marketing strategies using R. By analyzing consumer data, the project can identify distinct customer groups, enabling more targeted and effective marketing campaigns tailored to specific audience segments.
 Airbnb Housing Factors Influencing Prices Project
Airbnb Housing Factors Influencing Prices Project
The objective of this Python project is to analyze various factors affecting Airbnb pricing. By examining data on property features, locations, and host attributes, the study identifies key determinants that influence rental prices, providing insights for hosts to optimize their listings.
 Capital One Fictional Company Credit Card Customer Churn
Capital One Fictional Company Credit Card Customer Churn
This project develops a sophisticated machine learning framework using AdaBoost and advanced feature engineering to predict credit card customer churn with 78.61% accuracy, achieving an exceptional 89.2% ROI through targeted retention campaigns. The solution combines SMOTEENN sampling for class imbalance, comprehensive behavioral analysis, and an interactive Streamlit dashboard to provide real-time risk assessment and actionable insights that prevent customer attrition and generate $384,750 in annual net business benefit.
 Predicting Medical Insurance Premiums with Ensemble and Gradient Boosting ML Methods
Predicting Medical Insurance Premiums with Ensemble and Gradient Boosting ML Methods
This class project develops a ML framework using XGBoost regression and K-means clustering to predict medical insurance premiums with 80.3% accuracy (R²), achieving superior performance over traditional statistical models through advanced feature engineering of health profiles including age, BMI, chronic diseases, and surgical history. The solution combines predictive modeling with risk stratification into four distinct tiers (Low to Very High Risk) and delivers actionable insights through an interactive R Shiny dashboard (as a personal future work) that enables real-time premium calculations and personalized pricing strategies for insurance underwriters.
Micro Projects / Job Simulations
Micro project I have worked on:
-
Financial News Sentiment Analysis for Stock Insights
- This financial news analytics project - for my CS680 Data Mining class - is designed to predict the sentiment of stock headlines and assess how well different machine learning and deep learning models can classify market sentiment. By combining traditional methods like TF-IDF with SVMs and cutting-edge deep learning models like BiLSTM, BERT, and FinBERT, this project evaluates which approaches best uncover the emotional tone behind stock market news.
-
Food Consumer Price Index Inflation R Shiny Dashboard
- This class group project - for my DATA-615 Data Science class - aims to develop an interactive Shiny app that visualizes the Monthly Cost of Goods in the U.S. over the past 10 years, focusing on food Consumer Price Index (CPI) inflation using data from the Federal Reserve Economic Data (FRED). The app automates CPI data collection and applies a range of econometric and time series forecasting models—including ARIMA, SARIMA (Seasonal ARIMA), Holt-Winters, Prophet, and Simple Exponential Smoothing (SES)—to analyze trends and predict future inflation for categories like “Dairy,” “Meat, “Fruit,” “Baked Goods” and “Alcoholic Beverages.” It also incorporates volatility modeling techniques such as GARCH (Generalized Autoregressive Conditional Heteroskedasticity) and EWMA (Exponentially Weighted Moving Average) to assess fluctuations in food prices over time, offering users an interactive, data-driven exploration of food inflation dynamics in the U.S.
-
Lloyds Banking Data Science Forage Job Simulation: Customer Retention Enhancement through Predictive Analytics
- This project simulates a business-critical engagement with Lloyds Banking Group, aimed at reducing customer churn for its subsidiary, SmartBank. It leverages predictive analytics and supervised machine learning techniques to identify at-risk customers, enabling the delivery of strategic retention interventions. The case study demonstrates how data science can support financial institutions in protecting revenue, improving client satisfaction, and optimizing digital engagement channels.
-
Accenture Data Analytics and Visualization Forage Job Simulation: Social Buzz Content Popularity Data Analysis
- This project simulates a real-world data analytics engagement with Accenture, in partnership with the fast-growing social media platform Social Buzz. The objective was to analyze the platform’s massive volume of user-generated content and determine the top-performing content categories based on aggregate popularity scores.
-
API scraping, Data Cleaning and Visualisation
- Mortgage Rate Delinquency vs. Unemployment Analysis: In this file, I investigated the relationship between mortgage delinquency rates and unemployment trends using Python Plotly and FRED API. Utilizing economic data, the analysis explores correlations and potential causations, offering insights into how employment fluctuations impact mortgage repayments.
-
Simple Option Pricing Model (AAPL Stock)
- The European option pricing model uses Black-Scholes closed-form solutions to value AAPL call/put options, processing 67 contracts across multiple expiration dates and calculating theoretical prices, Greeks, and in-the-money probabilities using Python. Then, it was identified that there was a 53% pricing gap between the theoretical value ($2.83) and the market price ($5.97). Volatility smile patterns (0.30-0.60 IV range) were analyzed, and trading volume concentration at $300+ strikes was discovered, indicating bullish sentiment through time-series visualization.
Certifications
- IBM Data Science Professional Certificate
- Microsoft Azure Fundamentals (AZ-900) Cert Prep by Microsoft Press -> Passed the AZ-900 exam at June 2025
Skills
- Programming Languages: Python, R, SQL, HTML, CSS, PySpark, Apache Airflow, Tableau, Power BI, Excel
- Libraries & Tools: Pandas, NumPy, Scikit-learn
- Data Visualization: Matplotlib, Seaborn, ggplot2
- Machine Learning: Supervised/Unsupervised Learning, Tensorflow, PyTorch
- Data Engineering: ETL, Data Warehousing, Data Mining
- Cloud Storage: Docker, AWS, Azure
- Other: Git
- Medium writing: Medium
Contact
You can reach out to me via email or connect with me on LinkedIn.